Klatt Voice Synthesis
GS_Play includes a built-in text-to-speech system based on Klatt formant synthesis. The KlattVoiceComponent converts text to speech in real time with configurable voice parameters. Voices are positioned in 3D space and attenuate with distance, making synthesized speech feel like it comes from the character speaking.
For component properties, voice parameter details, and the phoneme mapping system, see the Framework API reference.
Contents
How It Works
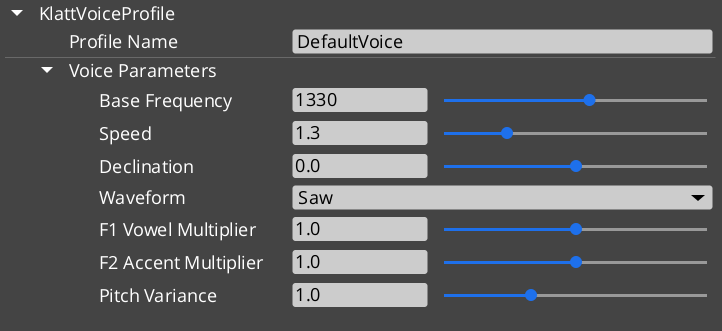
- Configure a voice using a KlattVoiceProfile — set frequency, speed, waveform, formants, and pitch variance.
- Assign a KlattPhonemeMap — maps text characters to ARPABET phonemes for pronunciation.
- Speak text from ScriptCanvas or C++ — the system converts text to phonemes and synthesizes audio in real time.
- Position in 3D — the voice component uses KlattSpatialConfig for 3D audio positioning relative to the entity.
Voice Configuration
| Parameter | What It Controls |
|---|---|
| Frequency | Base voice pitch. |
| Speed | Speech rate. |
| Waveform | Voice quality — Saw, Triangle, Sin, Square, Pulse, Noise, Warble. |
| Formants | Vocal tract resonance characteristics. |
| Pitch Variance | Random pitch variation for natural-sounding speech. |
| Declination | Pitch drop over the course of a sentence. |
KTT Tags
KTT (Klatt Text Tags) allow inline parameter changes within speech text for expressive delivery:
"Hello <speed=0.5>world</speed>, how are <pitch=1.2>you</pitch>?"
The KlattCommandParser processes these tags during speech synthesis, enabling mid-sentence changes to speed, pitch, and other voice parameters.
For the complete tag reference — all attributes, value ranges, and reset behavior — see the Framework API: KTT Voice Tags.
Phoneme Maps
Two base phoneme maps are available:
| Map | Description |
|---|---|
| SoLoud_Default | Simple default mapping. |
| CMU_Full | Full CMU pronunciation dictionary mapping. |
Custom phoneme overrides allow project-specific word pronunciations (character names, fantasy terms) without modifying the base map.
3D Spatial Audio
The KlattSpatialConfig controls how synthesized speech is positioned in 3D:
- Voices attenuate with distance from the listener.
- The KlattVoiceSystemComponent tracks the listener position and updates all active voices.
- Multiple characters can speak simultaneously with correct spatial positioning.
Quick Reference
| Need | Bus | Method |
|---|---|---|
| Control a voice | KlattVoiceRequestBus | Voice synthesis methods (entity-addressed) |
| System-level voice control | KlattVoiceSystemRequestBus | Listener tracking, engine management |
Glossary
| Term | Meaning |
|---|---|
| Klatt Synthesis | A formant-based speech synthesis method that generates voice from frequency parameters |
| KTT Tags | Inline text tags that modify voice parameters mid-sentence during synthesis |
| Phoneme Map | A mapping from text characters to ARPABET phonemes for pronunciation |
| KlattSpatialConfig | Configuration for 3D audio positioning and distance attenuation of synthesized speech |
For full definitions, see the Glossary.
See Also
For the full API, component properties, and C++ extension guide:
For related systems:
Get GS_Audio
GS_Audio — Explore this gem on the product page and add it to your project.